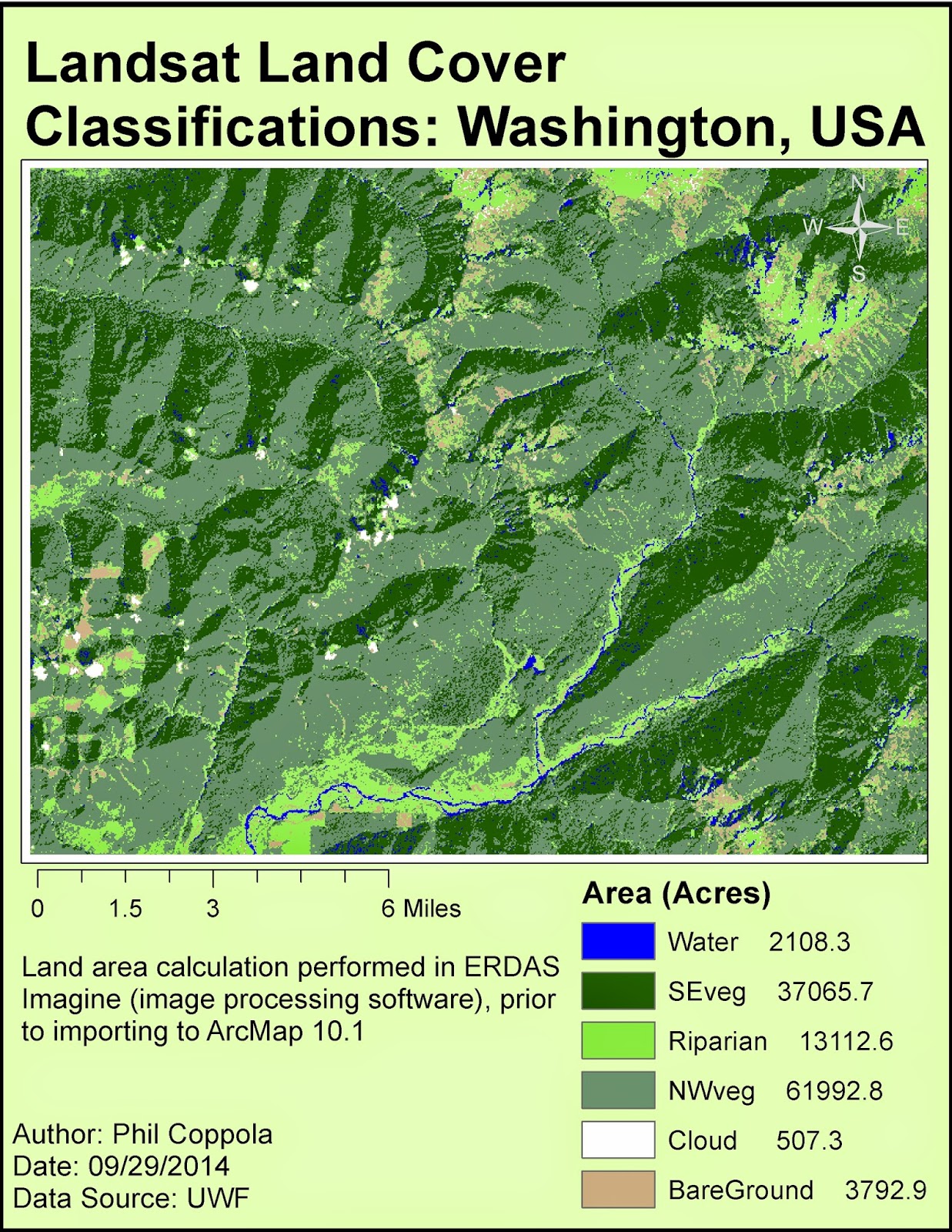
 |
| Final map output of landcover generated from Landsat data first processed in ERDAS Imagine and ultimately in ArcMap. |
Tuesday, September 30, 2014
Module 5a Lab: Intro to ERDAS Imagine and Digital Data 1
Wednesday, September 24, 2014
Lab 4 – Building Networks
This weeks lab involved network analysis. Routes were determined under a few different conditions including turn restrictions and predicted traffic. Turn restrictions are relevant when dealing with one-way streets and large road medians. Predicted traffic influences the time cost of traversing certain roads. Ultimately, adding model inputs changes the optimal route; however, the significance of the change may be minimal.
Tuesday, September 23, 2014
Module 4: Ground Truthing and Accuracy Assessment
 |
| A map depicting accuracy proofing of LULC data of Pascagoula, MS. |
The overall accuracy is determined by comparing random points placed on the original LULC map to those same points found in Google StreetView or aerial imagery. The overall accuracy of the LULC is determined by the number of "true" points divided by the total points. The accuracy of my LULC map was 77%.
Wednesday, September 17, 2014
Lab 3 – Determining Quality of Road Networks
 |
| A comparison of "completeness" between the national TIGER data set and a local, county-level, data set. |
This was applied in lab by assessing the completeness, defined as road length, between a local and national road data set. The map product at the right shows the comparison.
Tuesday, September 16, 2014
Lab 3: Land Use / Land Cover Classification Mapping
 |
| Above: Map of land cover land use classification of Pascagoula, Mississippi using USGS LCLU Level II classification scheme. |
Wednesday, September 10, 2014
Lab 2: Determining Quality of Road Networks

Digitized
features of the road network database from the city of Albuquerque tested 13.09
feet horizontal accuracy at the 95% confidence level using NSSDA testing
procedures.
Digitized
features of the road network database from StreetMaps USA tested 688.94 feet horizontal
accuracy at the 95% confidence level using NSSDA testing procedures.
Tuesday, September 9, 2014
Module 2 Lab: Visual Interpretation of Aerial Images


In the second exercise, specific features were identified using size and shape, patterns, associations, and shadows. Once a single object is positively identified (with a high degree of certainty) than it can be used as a reference in identifying other features. For example, once you locate and identify a road, you can confirm the identity of a vehicle. Then a building can be identied. Because these aerial images have no scale to reference, within-image references are very useful. A knowledge of the area (Pensacola BEach in map 2 at right) allows the user to determine water and pier features.
Wednesday, September 3, 2014
Lab 1: Calculating Metrics for Spatial Data Quality

As part of the lab, we were provided an array of waypoints that were collected from a single geographic point using a Garmin GPS device. We then had to calculate estimates of precision and accuracy after we were then given the "true" reference location. Below are two outputs of these calculations:
Horizontal Precision (68%): 4.45 meters
Horizontal Accuracy = 3.23 meters
Horizontal precision, which is a metric of the clustering of repeated measurements of a data point, was calculated by determining the average distance of all the repeated measurements to the average of these measurements. The accuracy was calculated as the difference between the average point from the repeated measurements and a given "true" reference point.
Subscribe to:
Comments (Atom)